


188 Messages
•
7K Points
Still Images wrongly tagged with language when there is no text
I have encountered a new problem with the new galleries in the desktop version:
I have added 2 new still images to this Australian TV Show https://www.imdb.com/title/tt1988386
Episode: https://www.imdb.com/title/tt2209111
Images: rm1939710209 tagged to language English, it doesn't give the possibility to untag any language, because it doesn't show any language when trying to edit the image to correct this error:

Here is an image of the submission, no language was added:
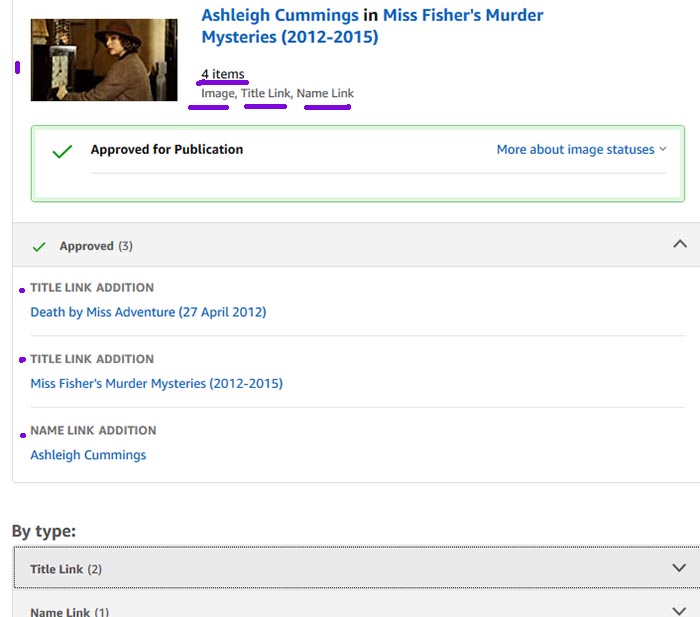


Again, 5 items approved: the image itself, 2 name links (both actresses) and 2 title links (tv show and episode), as seen in the screenshot. No language at all, because still images doesn't allow language tags and there is absolutely no language in the image.
I have to re-submit the images to see if this was a one time mistake, but it happened again:
Check it out please:
First Image:
#200908-081450-083102
#200908-161023-045802
Duplicate deletion:
#200910-090400-022802
Because the "Language: English" happened in bith contributions, so I had to delete one of the duplicates. I was trying to resolve the issue by myself before bringing it here.
Second Image:
#200908-080152-157902
#200908-160952-030902
Duplicate deletion:
#200910-090502-836802
Because the "Language: Italian" happened in both contributions again, so I had to delete one of the duplicates. I was trying to resolve the issue by myself before bringing it here, I didn't wanted to cause any more trouble.
Can you please check and tell me why is this happening? Is this a bug or am I doing something wrong regarding this 2 specific images? I have verified and there is no metadata interfering.
I am looking forward to your response, thank you very much in advance.
Accepted Solution
Grayson
Employee
•
578 Messages
•
11.2K Points
6 years ago
Hey - language detection for images is done automatically by an API, supported by the language additions that users make to images. Unfortunately sometimes the API will incorrectly tag a language where it is not needed.
I've removed the language tags and I can see that your delete submission has been approved. If there's anything left to do on this one let me know and I'll take care of it.
2